자바 메시징 서비스 (JMS) 사양은 자바 기반의 지점간 (point-to-point, P2P) 메시징과 publish/subscribe (P/S) 메시징에 대한 표준을 열거한다. Sun은 현재 12개의 라이선스 받은 JMS 구현자 목록을 가지고 있고 16개의 라이선스 받지 않은 구현자를 가지고 있다. 구조적으로 JMS는 JDBC API와 유사한데, 둘 다 적은 수의 클래스를, 그러나 많은 인터페이스 집합을 정의하기 때문이다. 이 인터페이스들은 구현되어져야 하고, 여기에 상응하는 구현들도 동일하게 행동할 것이다.
대부분의 데이터베이스의 경우 행동의 유사성은 JDBC 인터페이스 구현으로 끝난다. SQL 준수 수준과 독자적인 절차적 SQL 확장 (Oracle의 PL/SQL과 Sybase의 Transact-SQL등)의 차이로 인해 데이터베이스 서비스에 접근해서 이를 사용하기 위해 작성된 코드에 상당한 차이가 있을 수 있다.
JMS에서는 그렇지 않다. 최소의 노력과 이 글에서 내가 제시한 절차들을 따름으로서 여러분은 여러분의 JMS 클라이언트 코드가 여러분이 사용하고 있는 벤더 구현을 알지 못하게 만들 수 있다. 여러분이 JMS 메시지 처리에 대한 기본적인 이해를 가지고 있다고 가정하지만, 기본 개념과 용어를 간단하게 살펴보면서 시작해보자.
JMS 아키텍처
메시지를 보내고 받는 기본은 연결인데,이는 JVM 외부에 자원을 할당하는 책임을 가지고 있다. JMS 벤더는 보통 P2P 트랜잭션을 위해 적어도 하나의 QueueConnection 을, P/S 트랜잭션을 위해 TopicConnection 을 구현할 것이다. 이들 접속은 Session 을 제공하는데, 이것은 메시지의 전송과 수신을 관리하는 생성자이다.
P2P 트랜잭션 관리를 위한 기본 생성자는 QueueSender와 QueueReceiver이고, P/S 트랜잭션 관리를 위한 생성자는 TopicSubscriber과 TopicPublisher이다. Topic 객체와 Queue 객체는 각 메시지의 수신지와 출처를 나타내는 특정 정보를 캡슐화한다. 이 계층이 그림 1에 나와 있다.
그림 1. JMS 클래스 계층

request/response 지원 클래스 등의 다른 생성자와 애플리케이션 서버에 고유한 기능들은 JMS 표준 (참고 자료 )에 나와있다.
다른 유형의 연결 설정
연결은 JMS 서버와의 상호작용을 위한 진입점이기 때문에, 각 연결 인터페이스를 구현하려면 자체적인 JMS 서버의 인스턴스에 어떻게 연결하는지를 알아야 한다. 기반이 되는 연결 프로토콜의 상세사항은 각 벤더마다 다른 경우가 많기 때문에, 유효한 연결 설정에 필요한 정보도 각 벤더마다 다르다.
대부분의 벤더는 연결이 동적으로 설정될 수 있도록 한다. 즉 연결 클래스의 생성자를 공개적으로 정의하여, 프로그래머들이 필요한 연결 정보를 정의할 수 있도록 하고 있다. 대부분의 벤더는 호출에 대응해 연결을 반환하는 factory 클래스를 제공한다.
연결 factory의 경우 factory 클래스는 독자적인 연결 정보를 가지고 미리 로딩되어있는 연결을 반환할 수 있다. 벤더가 정의한 factory 클래스는 프로그래머가 접속 매개변수를 설정할 수 있도록 하는 메소드들을 보여 줄 것이며, 이 접속 매개변수들에는 factory가 반환하는 접속의 특성이 들어 있다.
벤더 API가 다른 부분
이 모두를 좀 더 구체화하기 위해 몇몇 QueueConnection 과 QueueConnectionFactory 구현 제품의 생성자, 접속 factory 및 설정 메소드들을 살펴보자. (일부 경우에는 오버로드된 생성자가 많이 있음에 유의한다.; 나는 각 경우에 대해 한 개씩만 보여주겠다.)
java.lang.String socketFactory: 소켓 factory의 클래스 명
java.lang.String hostname: JMS 서버의 호스트 명
int port: JMS 서버의 포트
long keepalive: 활동 주기
다음 코드는 swiftMQ QueueConnectionFactory 객체를 생성하는 방법이다. :
IIT SwiftMQ 2.1.3 QueueConnectionFactory 생성자 매개변수
QueueConnectionFactory qcf = (QueueConnectionFactory) new
com.swiftmq.jms.ConnectionFactoryImpl
("com.swiftmq.net.PlainSocketFactory", "myhost",4001,60000);
|
java.lang.String brokerURL: URL (in the form [protocol://]hostname[:port])
java.lang.String connectID: 접속을 구별하기 위한 ID 문자열
java.lang.String username: 기본 사용자명
java.lang.String password: 기본 패스워드
다음은 Progress SonicMQ QueueConnectionFactory 객체를 생성하는 샘플 코드이다:
Progress SonicMQ 3.5 QueueConnection 생성자 매개변수
progress.message.jclient.QueueConnection queueConnection = new
progress.message.jclient.QueueConnection("tcp://myhost:2506",
"ServiceRequest", "username", "password");
|
우리가 살펴볼 마지막 예제는 IBM MQSeries 구현이다. MQSeries는 연결 생성자를 이용하지 않는다. 대신 여러분은 동적으로 연결을 생성하기 위해 연결 factory를 구축해야 하는데, 이는 연결을 제공하기 위한 메소드를 제공한다. 매개변수가 없는 생성자를 만들기 위한 코드는 다음과 같다.:
MQSeries (MA88)
MQQueueConnectionFactory = new
MQQueueConnectionFactory();
|
연결 factory의 생성자는 매개변수가 없기 때문에, factory는 factory가 제공할 연결의 특성들을 제어하기 위해 호출될 수 있는 돌연변이 메소드를 가지고 있어야 한다.:
setTransportType(int x): 다음 옵션 중 하나에 전송 유형을 설정한다. :
JMSC.MQJMS_TP_BINDINGS_MQ: MQSeries 서버가 클라이언트와 동일한 호스트에 있을 때 사용된다.
JMSC.MQJMS_TP_CLIENT_MQ_TCPIP: MQSeries 서버가 클라이언트와 다른 호스트에 있을 때 사용된다.
setQueueManager(String x): 큐 관리자의 이름을 설정한다.
setHostName(String hostname): 클라이언트만 해당됨, 호스트의 이름을 설정한다.
setPort(int port): 클라이언트 연결을 위한 포트를 설정한다.
setChannel(String x): 클라이언트에만 해당됨, 사용할 채널을 설정한다.
다음은 MQSeries QueueConnectionFactory를 생성하고 특정 큐 관리자로 접속하게 하는 샘플 코드이다. :
com.ibm.mq.jms.MQQueueConnectionFactory factory = new
com.ibm.mq.jms.MQQueueConnectionFactory();
factory.setQueueManager("QMGR");
com.ibm.mq.jms.MQQueueConnection connection =
factory.createQueueConnection();
|
벤더에 독립적인 코드 생성에서의 JNDI의 역할
간략하게 살펴보았듯이, 각 벤더는 자체적인 별개의 연결 매개변수를 채택하고 있다. 그렇다면 이들 모두를 여러분 코드에 어떻게 투명하게 지원할 것인가? 표준 솔루션은 네이밍 서비스를 사용하여 사전 설정된 ConnectionFactory를 유지하는 것이다. 실행 시에 여러분의 코드는 ConnectionFactory를 검색하고 여기에서 반환되는 연결을 여러분의 JMS 서버에 투명하게 연결시킬 수 있을 것이다. 간단히 여러분의 네이밍 서비스에서 정확하게 구성된 연결 factory들만을 관리하면 되기 때문에 코드를 유지보수하고 재구축할 필요가 없어진다.
Java Naming and Directory Interface (JNDI)는 네이밍 서비스와 인터페이스하는 가장 일반적인 방법이다. JNDI는 구현되어야 하는 인터페이스 세트를 간단히 정의한다는 점에서 JMS와 유사하다. JNDI를 구현하는 모든 네이밍 서비스는 하나의 표준 API하에 접근된다.
JNDI는 벤더에 독립적인 코드를 작성하려는 우리 노력의 중심이다. 벤더에 독립적인 방식으로 네이밍 서비스에 접근할 수 있는 방법을 제공하기 때문이다. JNDI는 우리가 위 섹션에서 설명한 독자적 구현 제품에 관해 걱정하지 않고 네이밍 서비스에서 올바른 객체를 검색하기 위한 코드 작성에만 신경을 쓰도록 해준다.
JMS 서버로의 접속
연결 factory를 생성하고 이를 미리 구성하여 여러분의 네이밍 서비스에 결합시킴으로써, 여러분의 메시징 서비스에서 특정 벤더에 국한된 연결 매개변수를 감출 수 있다. 여러분의 코드가 관련되어 있는 한 여러분은 일반적인 javax.jms.Connection 객체를 사용하고 있다. 벤더 구현은 인터페이스 뒤에 숨겨진다.
JMS 사양은 관리자에 의해 생성되고 JMS 클라이언트가 사용할 구성 정보를 가지고 있는 객체를 JMS 관리 객체로 지칭하고 있다. 관리 객체는 JNDI에 의존적이지 않지만, JNDI 이름공간에서 결합되고 검색될 수 있음을 암시한다.
Listing 1과 Listing 2는 JMS 서버 (이 경우에는 SwiftMQ)에 접속하기 위한 두 가지 다른 방식을 보여준다. 벤더에 의존하는 코드를 이용하는 방식과 벤더에 독립적인 코드를 이용하는 방식이 그것이다.
Listing 1. 벤더에 의존적인 접속 방법
1.QueueConnectionFactory queueConnectionFactory =
(QueueConnectionFactory) new
com.swiftmq.jms.ConnectionFactoryImpl
("com.swiftmq.net.PlainSocketFactory", "localhost",4001,60000);
2.QueueConnection queueConnection =
queueConnectionFactory.createQueueConnection();
|
Listing 2. 벤더에 중립적인 접속 방법
1.Properties p = new Properties();
2.p.put(Context.INITIAL_CONTEXT_FACTORY,
"com.swiftmq.jndi.InitialContextFactoryImpl");
3.p.put(Context.PROVIDER_URL,"smqp://localhost:4001");
4.ctx = new InitialContext(p);
5.qcf = (QueueConnectionFactory)ctx.lookup("MyQCF");
6.oQueueConnection queueConnection =
queueConnectionFactory.createQueueConnection();
|
코드를 나누는 방법
여러분들은 우선 벤더에 독립적인 코드가 몇 행을 더 가지고 있다는 점을 알아차릴 것이다. 이는 우리가 네이밍 서비스에 접속해야 하기 때문이다. 그러나 전체 프로그램에서 한번만 네이밍 서비스에 접속하면 된다는 사실을 염두에 두어야 한다. 따라서 추가적인 몇 행은 그 가치가 있다. (필요할 때마다 원격 context를 인스턴트화 하는 대신 네이밍 서비스를 재사용하도록 한다.)
네이밍 서비스와의 상호작용과 준비는 벤더에 중립적인 메시징 코드를 작성하는데 중요하다. 벤더에 의존적인 코드 예제에서 우리는 연결을 제공할 factory를 작성하기 위해 SwiftMQ 구현의 QueueConnectionFactory 생성자를 사용하였다. Listing 1의 1행에서와 같이, 이 구현을 위해 우리는 벤더에 독자적인 클래스를 포함시켜야 할 뿐 아니라 QueueConnectionFactory 생성자에게 특정 벤더에 국한된 매개변수도 보내야 한다.
벤더에 중립적인 예제에서, 특정 벤더에 국한된 코드는 없지만 우리는 초기 context factory와 네이밍 서비스를 제공하는 URL 뿐 아니라 QueueConnectionFactory의 바인딩 명도 알아야 한다. 바인딩 명의 경우 네이밍 서비스를 적절하게 유지하면 어떤 벤더가 제공하는 객체라도 여러분의 JNDI 트리에 바인딩시킬 수 있을 것이다. 따라서 벤더가 바뀌더라도 바인딩 명을 바꿀 필요가 없다. JNDI context의 경우 특성 파일에 매개변수 문자열 (Listing 2의 2행과 3행)을 저장하는 것이 일반적이다. 이렇게 하면 JMS 벤더가 바뀔 경우 간단히 특성 파일을 바꾸기만 하면 된다.
이 기법은 여러분에게 네이밍 서비스와 관련하여 유연성과 이식성을 제공한다는 점도 흥미로운 일이다. 많은 JMS 벤더 (Fiorano, SwiftMQ등)들이 자체적인 JNDI 서비스를 제공하지만, 여러분은 네이밍 서비스를 JMS 서비스에서 분리하고 싶어할 수도 있다. (예를 들어, 여러분은 여러분의 연결 factory를 중앙의 LDAP 서버에 저장하려 할 수 있다.)
다음은 각기 다른 JNDI 연결들을 가져올 특성 파일 엔트리의 예이다.:
java.naming.provider.url=smqp://myhost:4001
java.naming.factory.initial=com.swiftmq.jndi.InitialContextFactoryImpl
IBM WebSphere JNDI 서비스
java.naming.provider.url=iiop://myhost:9001
java.naming.factory.initial= com.ibm.websphere.naming.WsnInitialContextFactory
iPlanet 디렉토리 서버 (LDAP)
java.naming.provider.url=ldap://myhost:389
java.naming.factory.initial=com.sun.jndi.ldap.LdapCtxFactory
BEA WebLogic JNDI 서비스
java.naming.provider.url=t3://myhost:7001
java.naming.factory.initial=weblogic.jndi.WLInitialContextFactory
File System JNDI 서비스
java.naming.provider.url=file:/tmp/stuff
java.naming.factory.initial=com.sun.jndi.fscontext.RefFSContextFactory
여러분의 소스 코드는 벤더 클래스를 직접 참조하지 않을 수 있지만 벤더 클래스는 이름으로 JVM에 동적으로 로딩된다는 점에 주의하라. 따라서 실행 시에 여러분 프로그램의 클래스경로에 이들이 있어야 한다. JNDI와 JMS 클래스에서도 마찬가지이다.
특성 파일 설정하기
따라서 여기에서 우리는 JNDI 서비스에 연결하는 방법과 코드를 재컴파일하지 않고 상이한 JNDI와 JMS 구현으로부터 연결하는 방법을 알아야 한다. 특성 파일이 어떻게 설정되는지와 JNDI 연결에서 특성 파일이 수행하는 역할을 살펴보면서 지금까지 설명한 정보들을 종합해 보자.
JNDI 연결을 위한 기본 클래스는 javax.naming.InitialContext이다. InitialDirContext와 같이 디렉토리 작업에 국한된 InitialContext 의 하위 클래스도 있지만, 일반 클래스가 그 작업을 수행할 것이다. InitialContext 가 구축되면 환경 (시스템 특성이나 애플릿 매개변수)으로부터 JNDI 매개변수를 가져오거나 특정한 jndi.properites 파일을 찾는다.
이 작업은 J2SE 1.3.1 javadoc에 다음과 같이 설명되어 있다.:
JNDI는 다음 두 소스의 값을 차례로 합하여 각 특성의 값을 결정한다.
- 생성자의 환경 변수에서 처음 나타나는 특성과 (적합한 특성에 대한) 애플릿 매개변수와 시스템 특성
- 애플리케이션 자원 파일 (jndi.properties)
추가적인 특성들
지금까지 우리는 접속 제공자의 URL와 InitialContext factory 명(name)이라는 두개의 매개변수만 살펴보았다. 실제로는 훨씬 더 많은 특성 변수들이 제공될 수 있다. 우리가 살펴본 두 가지를 제외하고 가장 일반적인 것은 보안 처리된 JNDI store에 접근시 여러분의 신원을 확인해주는 사용자 명과 패스워드이다. 이 매개변수들은 다음과 같다.:
java.naming.security.principal (사용자명)
java.naming.security.credentials (패스워드)
파일 로딩하기
나는 여러분 애플리케이션의 모든 런타임 구성 매개변수를 하나의 애플리케이션 특성 파일에 두고 거기에 JNDI 매개변수를 포함시킬 것을 권한다. 모든 매개변수를 한 곳에 두면 불확실성이 없어진다. 그러면 여러분은 애플리케이션 특성 파일을 로드하기 위한 몇 가지 옵션을 가진다. 여기서는 두 가지 예를 들겠다. 파일은 자원 번들로 로딩될 수도 있고, 또는 명령행 매개변수로 특성 파일의 이름과 위치를 전달할 수도 있다.각 방식은 각기 다른 장점을 가지고 있다.
파일 위치를 명령행 매개변수로 전달하는 것이 여러분 코드를 구성하는 가장 쉬운 방법이다. 매개변수는 간단히 애플리케이션의 시동을 수정하여 변경시킬 수 있다.
자원 번들로 파일을 로딩하면 두 가지 이점이 있다.:
- JVM의 위치에 따라 다른 자원 번들이 로딩될 수 있다. 예를 들어, application_en_US.properties 파일은 뉴욕의 JNDI 서비스를 가리키고, application_fr.properties 파일은 파리의 JNDI 서비스를 가리킨다.
- 자원 번들에서 특성을 로딩하는 것은 아키텍처와 플랫폼에 독립적인 방법이다. 자원 번들은 클래스 경로로부터 로딩되기 때문에
코드는 JVM의 명령행 매개변수를 읽을 수 있는지와 무관하다. 또한 EJB 컴포넌트와 같은 일부 컴포넌트들이 파일 입출력을 직접 이용하지 않기 때문에 자원 번들은 특성 파일의 내용을 로딩하는 더욱 편리한 방법을 제공한다.
상충되는 환경 설정에서 오는 혼란을 피하기 위해 나는 항상 내 특성 파일에서 읽은 JNDI 값으로 특성 인스턴스를 설정한다.
특성 파일 초기화 및 JNDI 검색
이 섹션에 나와 있는 코드는 특성 파일 초기화의 두 유형 (명령행 매개변수 및 자원 번들) 뿐 아니라 일반적인 JNDI 검색도 보여준다. 우선 Listing 3에 나와 있는 application_fr.properties라는 구성 파일 샘플을 살펴보자.:
Listing 3. PropertiesManagement.properties
java.naming.provider.url=smqp://localhost:4001
java.naming.factory.initial=com.swiftmq.jndi.InitialContextFactoryImpl
java.naming.security.principal=admin
java.naming.security.credentials=secret
com.nickman.neutraljms.QueueConnectionFactory=myQueueConnectionFactory
com.nickman.neutraljms.TopicConnectionFactory=myQueueConnectionFactory
com.nickman.neutraljms.Queue=testqueue@router1
com.nickman.neutraljms.Topic=testtopic
|
특성 파일 정의
이제 특성 파일을 읽기 위한 코드를 살펴보자. 앞에서 설명했듯이, 여러분은 JNDI 접속 매개변수를 결정하기 위한 두 가지 옵션을 가지고 있다. Listing 4는 JNDI 특성을 검색하기 위한 샘플 코드이다.:
Listing 4. JNDI 특성 조회하기
package com.nickman.jndi;
import javax.naming.*; // For JNDI Interfaces
import java.util.*;
import java.io.*;
import javax.jms.*;
public class PropertiesManagement {
Properties jndiProperties = null;
Context ctx = null;
public static void main(String[] args) {
PropertiesManagement pm = new PropertiesManagement(args);
.
.
public PropertiesManagement(String[] args) {
jndiProperties = new Properties();
if(args.length>0) {
try {
loadFromFile(args[0]);
.
.
} else {
try {
loadFromResourceBundle();
.
.
private void loadFromFile(String fileName) throws Exception {
FileInputStream fis = null;
try {
fis = new FileInputStream(fileName);
jndiProperties.load(fis);
} finally {
try { fis.close(); } catch (Exception erx){}
}
}
private void loadFromResourceBundle() throws Exception {
String key = null;
String value = null;
ResourceBundle rb =
ResourceBundle.getBundle("PropertiesManagement");
Enumeration enum = rb.getKeys();
while(enum.hasMoreElements()) {
key = enum.nextElement().toString();
value = rb.getString(key);
jndiProperties.put(key, value);
}
}
|
이 글에서의 작업시 참조하기 위해 전체 소스 코드 파일을 다운로드 받을 수 있다.
코드를 나누는 방법
Listing 4는 특성 파일을 두 가지 다른 방식으로 로딩하기 위한 코드를 보여준다. 명령행 매개변수가 전달되면 코드는 이것이 완전한 조건을 갖춘 특성 파일명이라고 가정하며, loadFromFile(String fileName) 메소드를 사용해 특성이 로딩된다.
클래스는 다음과 같이 호출된다. :
java com.nickman.jndi.PropertiesManagement
c:\config\PropertiesManagement.properties
|
명령행 매개변수가 전달되지 않으면 코드는 loadFromResourceBundle() 메소드를 호출할 것이다. 이 메소드는 CLASSPATH에서 특성 파일을 찾는다. 따라서 클래스 경로에 이 파일의 디렉토리를 두어야 한다. 양 방식 모두에서 특성은 jndiProperties라는 특성 변수로 로딩된다.
I JNDI 서비스에 연결하기
Listing 5는 JNDI 서비스로의 연결을 보여준다. :
Listing 5. JNDI 연결
public void connectToJNDI() throws javax.naming.NamingException {
// jndiProperties was loaded from PropertiesManagement.properties
ctx = new InitialContext(jndiProperties);
System.out.println("Connected to " +
ctx.getEnvironment().get(Context.PROVIDER_URL));
}
|
위의 연결 코드는 아주 직접적이다. jndiProperties 변수는 InitialContext 생성자로 전달되고, 결과로 나오는 Context는 JNDI 서비스에 대한 일종의 "핸들"이다. javax.naming.Context 인터페이스가 사용 가능한 모든 환경 특성 변수들을 모두 표현하는 상수들의 셋트를 담고있다는 데 주의하는 것이 좋다.
구축된 Context로 우리는 Listing 6에서와 같이 JMS 객체 검색을 진행할 수 있다.:
Listing 6. JNDI 검색
public QueueConnectionFactory lookupQueueConnectionFactory()
throws javax.naming.NamingException {
return
(QueueConnectionFactory)ctx.lookup(jndiProperties.get
("com.nickman.neutraljms.QueueConnectionFactory").toString());
}
public Queue lookupQueue() throws javax.naming.NamingException {
return
(Queue)ctx.lookup(jndiProperties.get
("com.nickman.neutraljms.Queue").toString());
}
|
검색은 간단히 Context의 lookup(String name) 메소드를 호출하고, 우리가 원하는 객체가 바인딩될 이름으로 전달되는 과정이라고 볼 수 있다. 반환되는 객체는 올바른 클래스로 보내져야 하는데, 이 경우에는 표준 javax.jms 인터페이스중 하나가 될 것이다.
Destination 인터페이스
javax.jms.Destination 은 메시지가 전달될 특정 목적지를 캡슐화하는 인터페이스이다. Queue와 Topic 인터페이스는 모두 Destination 인터페이스를 확장한다. Destination 은 JMS가 관리하는 객체이기 때문에, Queues와 Topics도 마찬가지이다.
여러분은 JMS API가 Topic과 Queue 세션 클래스에 두개의 메소드를 가지고 있음을 알게 될 것이다.:
Topic TopicSession.createTopic(java.lang.String topicName)
Queue QueueSession.createQueue(java.lang.String topicName)
따라서 다음과 같은 질문을 던질 수 있다.: 하나의 문자열을 사용해 간단히 이를 참조할 수 있는데 왜 JNDI에 queue나 topic을 저장하는 수고를 해야 합니까? 그 이유는 아주 미묘하다.: 이를 이해하기 위해 javacdoc에서 다음을 인용하겠다.:
Destination 객체는 제공자(provider) 고유의 주소를 캡슐화한다. JMS API는 표준 주소 구문을 정의하지 않는다. 표준 주소 구문을 염두에 두더라도, 기존의 메시지 지향 미들웨어 (MOM) 제품들간의 주소 의미론간에 차이가 너무 커서 하나의 구문으로는 해결할 수 없다는 결론이 내려졌다.
Destination 은 관리되는 객체이기 때문에 자신의 주소 외에 제공자 고유의 구성 정보를 포함하고 있을 수 있다.
간단히 말해, 이것은 우리가 특정 JMS 제공자에 관한 상세사항을 JNDI에서 이름 공간을 검색하기 위해 사용되는 간단한 이름 뒤에 숨길 수 있다는 것이다. 나는 또한 JMS 클라이언트와 실제 JMS 목적지간에 중간층을 두면 아키텍쳐상에 추가적인 유연성이 주어진다는 것을 알았다. 클라이언트 코드는 myQueue라고 불리는 JNDI내의 이름공간을 참조할 수 있지만 관리자는 모든 벤더의 큐 수신지가 될 수 있는 객체를 그 이름공간에 할당할 수 있다. 이 개념이 그림 2에 나와 있다.
그림 2. 수신지 유연성

골치 아픈 topics
JMS의 publish-and-subscribe 프레임워크는 벤더에 중립적이 되려는 우리의 작업을 왜곡시키는 몇 가지 기능을 정의한다. 많은 JMS 서버가 계층적 이름 공간이라는 개념을 지원하는데, 이는 P/S 메시지가 하나의 계층으로 분류될 수 있게 한다. 토픽 구독 클라이언트가 JMS 서버에 접속하면 계층의 특정 부분에 해당하는 메시지를 요청할 수 있다. 그림 3에 설명된 계층을 예로 살펴보자.:
그림 3. 샘플 계층

이를 좀 더 잘 이해하기 위해 예제 시나리오를 사용해보자. 가령 구독자 클라이언트가 서비스 내에 있는 모든 미국 주가 정보를 구독하고 싶어한다고 가정해보자. 정적인 구독의 경우 클라이언트는 미국 주가를 구독하기 위해 사전 구성된 topic을 나타내는 JMS 관리 객체를 간단히 검색하기만 하면 된다. JMS 벤더들마다 계층적인 구독을 표현하기 위해 다른 구문을 사용하기 때문이 이것이 이상적인 방법이 될 것이다. 그리고 이를 JNDI가 검색하는 객체 뒤로 숨김으로써 클라이언트는 기반이 되는 JMS 구현을 알지 못할 것이다.
그러나 수백개의 다른 구독 "cell"을 제공하며 50개의 다른 단계를 포함하고 있는 한 계층을 생각해보자. 또한 그 계층이 동적이며 관리자가 이를 지속적으로 늘린다고 생각해보자. 그런 경우 JMS 관리자가 가능한 모든 구독을 표시하는데 필요한 JMS 관리 객체를 모두 생성하는 것은 불가능할 것이다. 더구나 계층 선택은 클라이언트 애플리케이션을 지원하도록 유연하고 동적이어야 한다.
이런 상황에서는 topic 명이 실행 시에 정의되도록 하는 것이 더 적합할 것이다. 문제는 계층을 표현하기 위해 사용되는 구문이 벤더마다 틀리다는 점이다. 다음 코드들은 세 개의 다른 벤더가 사용하는 구독 구문들이다.
MQSeries JMS
Topic topicEqUs = topicSession.createTopic("topic://Prices/Equity/US");
Topic topicEqAll = topicSession.createTopic("topic://Prices/Equity/*");
|
SonicMQ 3.5
Topic topicEqUs = topicSession.createTopic("Prices.Equity.US");
Topic topicEqAll = topicSession.createTopic("Prices.Equity.*");
|
SwiftMQ 2.1.3
Topic topicEqUs = topicSession.createTopic("Prices.Equity.US");
Topic topicEqAll = topicSession.createTopic("Prices.Equity.%");
|
MQSeries JMS 구현은 다른 두개의 구현과 다른 topic 구분자를 채택했다는 점에 주의한다. (거의 모든 다른 벤더들은 마침표를 사용하는데 MQSeries는 사선 표시를 사용한다.)
위에서 설명한 문자들과 별도로, topic 명에 나타날 수 있는 벤더마다 고유한 문자열들이 있다. 예를 들어, SonicMQ는 상위 계층을 구분하기 위해 파운드 기호를 사용하고, MQSeries는 보통 API용으로 남겨둔 옵션을 표현하기 위해 topic명에 접미사를 붙인다. 거의 모든 JMS 벤더들이 다른 와일드카드를 채택하고 있기 때문에 실행 시에 토픽 명을 일률적으로 정의하는 것이 어렵다. 다행히도 이 문제에 대한 해결방법이 있다. 모든 특수 문자를 하나의 참조 소스에 저장하고 이 소스에서 문자들을 로드하여 실행 시에 사용하는 것이다.
참조 소스는 여러분의 애플리케이션 특성 파일이 될 수도 있고 JNDI 서비스가 될 수도 있다. 이를 보여주기 위해 Listing 7과 같이 우리의 PropertiesManagement.properties 파일에 topic 문자를 추가할 것이다:
Listing 7. topic 문자가 추가된 PropertiesManagement.properties
#Topic Delimiter For Sonic and Swift
com.nickman.neutraljms.TopicDelemiter=.
#Topic Delimiter for MQSeries
#com.nickman.neutraljms.TopicDelemiter=/
#Topic Wild Card For Sonic and MQSeries
com.nickman.neutraljms.TopicWildCard=*
#Topic Wild Card For Swift
#com.nickman.neutraljms.TopicWildCard=%
#Topic Prefix For MQSeries
#com.nickman.neutraljms.TopicPrefix=topic://
#Topic Prefix For All Others
com.nickman.neutraljms.TopicPrefix=
|
이들 엔트리가 추가되어 우리의 topic 구독 코드가 다음과 같이 되면 이 코드는 벤더에 독립적으로 될 것이다:
Listing 8. Topic 구독 코드
String delim =
jndiProperties.get("com.nickman.neutraljms.TopicDelemiter").toString();
String wildcard =
jndiProperties.get("com.nickman.neutraljms.TopicWildCard").toString();
Strung prefix =
jndiProperties.get("com.nickman.neutraljms.TopicPrefix").toString();
Topic topicEqUs = topicSession.createTopic("Prices" + delim +
"Equity" + delim + "US");
Topic topicEqAll = topicSession.createTopic("Prices" + delim +
"Equity" + delim + wildcard);
|
일단 여러분이 Listing 7에 나타난 외부 설정을 끝내고 나면 여러분은 여타의 벤더 고유 옵션을 처리하도록 이를 확장할 수 있다. 예를 들어, JMS 사양은 한 세션이 구현할 수 있는 두 개의 배달 (delivery) 모드를 정의하지만, Sonic MQ는 세 개의 배달모드를 추가적으로 더 지원한다. 배달 모드를 외부에서 정의함에 따라 여러분은 Sonic MQ의 독자적 확장자를 구현하는 한편 여러분 코드의 벤더 중립성을 유지할 수 있다.
원문 출처 : http://www.ibm.com/developerworks/kr/library/j-jmsvendor/
 PhotoRoverViewer.zip
PhotoRoverViewer.zip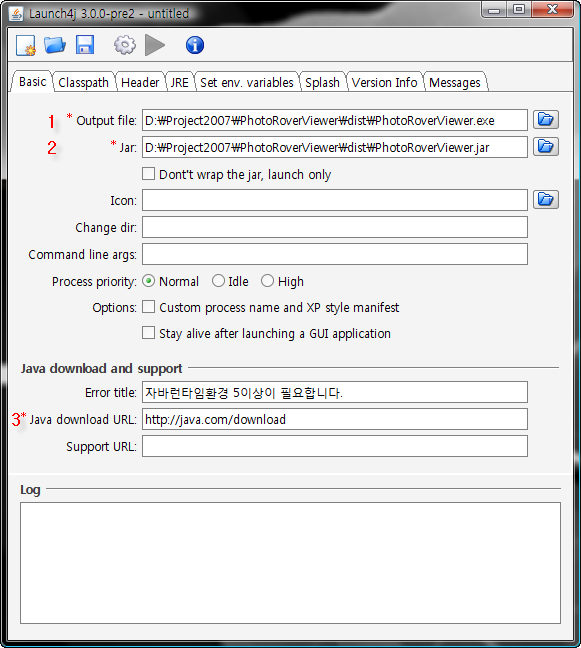
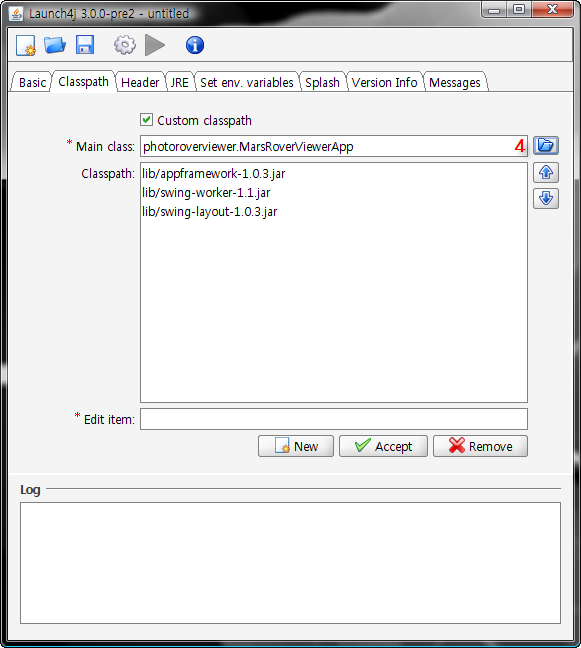
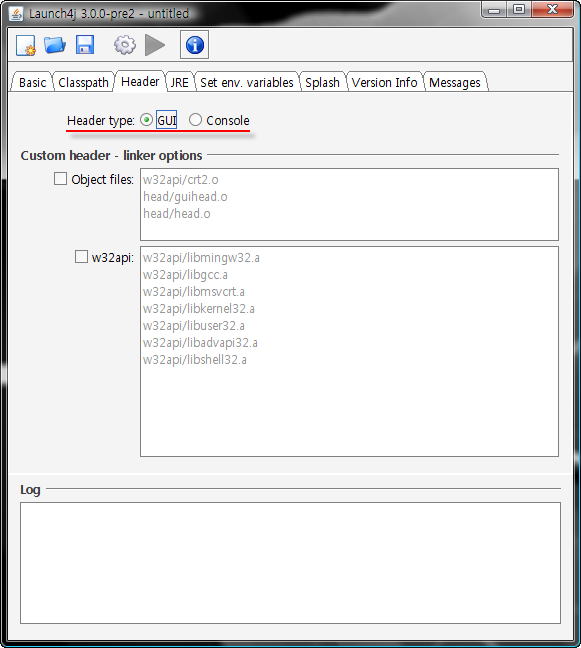
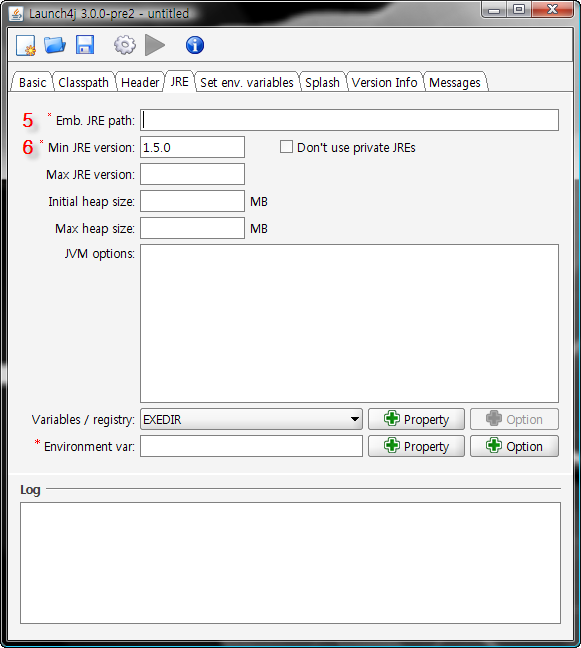



 os-javapdf-itextsample.jar
os-javapdf-itextsample.jar
좋은 정보 잘 보고 가요 ~ ^^
도움이 되셨다니 저도 기쁩니다.
저도 잘보고 갑니다.잘되는군요 ;)
좋은 정보 감사합니다. 그런데, lauch4j로 만든 exe를 실행할 때, 절대 경로가 영어로만 되어 있으면 문제 없는데, 절대 경로 상에 한글이 포함되어 있으면 실행이 안되는 문제가 있습니다. 혹시 해결 방법은 아시는지요..
많이 배우고 갑니다.
감사합니다. :)
여러글을 보다가 여기까지 왔네요..혹시
반대로는 가능한가요?
exe --> jar 형태로요?
공생공사님 안녕하세요.
http://stackoverflow.com/questions/7760126/how-to-convert-exe-file-to-jar-file 에도 님과 같은 질문 관련글이 있는데 대부분의 jar -> exe 컨버팅 도구의 경우 exe내부에 단순히 jar를 싸고 있는 형태로 패키징 하지 않고 .class 정보를 이용하여 실행파일을 생성해내기 때문에 exe에서 jar를 추출해 낼 수는 없습니다.
다만, jsmooth나 launch4j 라도 exe에 jar를 포함하는 형태가 아닌 단순히 jar를 실행하기위한 런처만 exe로 구성했다면 실행 jar가 어딘가에 위치하고 있을 확률은 존재합니다.
어떤 이유로 추출이 필요하신지 대강 짐작은 됩니다만, 가능하시면 원 개발자와 컨택하셔서 소스를 얻어내는 방안을 고민해보시는게 현실적일것 같습니다.
관리자만 볼 수 있는 댓글입니다.
질문 있습니다.
//자바어플리케이션을 실행할 PC에 자바구동환경( 자바런타임 JRE )이 미리 설치 되어 있지어야 한다는 약점이 있습니다.
이 때문에 자바 Swing/AWT등으로 작성된 GUI어플리케이션의 경우 어플리케이션 작성 후 Executable JAR파일을
윈도우용 실행 파일(exe)로 감싸는(Wrapping)하는 단계를 거치게 됩니다.
...라고 적혀있는데 조금만 밑으로 내려가면
//변환된 자바 exe파일을 실행할 PC에 자바런타임 환경이 없을경우 안내문구와 이동할 웹사이트를 기술합니다.
...라고 적혀있습니다. exe파일로 만들면 jre가 없는 환경에서도 실행될 수 있다는 말 아닌가요? 근데 왜 안내문구와 이동할 웹사이트가 필요한지 모르겠습니다.
jar 파일을 exe파일로 wrapping 하는 작업은 단순히 exe를 통해 jar파일을 실행시켜주는 역할만 하는 겁니다.
실행은 jvm 위에서 해야하므로, 환경이 되어야 작동이 가능합니다.
감사합니다 ㅎㅎ 큰 도움이 되었습니다