문자열 오브젝트의 길이는?
여러분의 텍스트 스트링의 길이는 얼마나 되는가? 사용자 입력이 데이터 필드 길이 제한 조건에 부합하는지 확인하기 위해선 그 답이 필요하다. 데이터베이스의 텍스트 필드는 입력을 일정한 길이로 제한하는 경우가 많으므로 텍스트를 제출하기 전에 길이를 확인할 필요가 있다. 이유야 어쨌든, 누구든지 이따금씩 텍스트 필드의 길이를 알아야 할 때가 있다. 많은 프로그래머들이 String 오브젝트의 length 메소드를 이용하여 그 정보를 얻으며, 대개의 경우 length 메소드는 올바른 솔루션을 제공한다. 하지만 이것이 String 오브젝트의 길이를 결정하는 유일한 방법은 아니며, 언제나 올바른 것도 아니다.
자바 플랫폼에서 텍스트 길이를 측정하는 데 세 개 이상의 일반적인 방법이 있다.
char코드 유닛의 수- 문자 또는 코드 포인트의 수
- 바이트의 수
char
자바 플랫폼은 유니코드 표준 을 사용하여 문자를 정의하는데, 이 유니코드 표준은 한때 고정 폭(U0000~UFFFF 범위 내의 16비트 값)으로 문자를 정의했다. U 접두사는 유효한 유니코드 문자 값을 16진수로 표시한다. 자바 언어는 편의상 char 타입에 대해 고정 폭 표준을 채택했고, 따라서 char 값은 어떠한 16비트 유니코드 문자라도 표현이 가능했다.
대부분의 프로그래머는 length 메소드에 대해 잘 알고 있고 있을 것이다. 아래의 코드는 예제 문자열에서 char 값의 수를 세는데, 예제 String 오브젝트에는 자바 언어의 \u 표기법으로 정의되는 몇 개의 단순 문자와 기타의 문자가 포함되어 있다는 점에 유의하기 바란다. \u 표기법은 16비트 char 값을 16진수로 정의하며 유니코드 표준에서 사용되는 U 표기법과 유사하다.
private String testString = "abcd\u5B66\uD800\uDF30";
int charCount = testString.length();
System.out.printf("char count: %d\n", charCount);
length 메소드는 String 오브젝트에서 char 값의 수를 센다. 이 예제 코드는 다음을 출력한다.
char count: 7
문자 유닛 수 세기
유니코드 버전 4.0이 UFFFF 이상 되는 상당히 큰 수의 새로운 문자를 정의하면서부터 16비트 char 타입은 더 이상 모든 문자를 표현할 수 없게 되었다. 따라서 자바 플랫폼 J2SE 5.0버전부터는 새로운 유니코드 문자를 16비트 char 값의 쌍(pair)으로 표현하며, 이를 surrogate pair 라고 부른다. 2개의 char 유닛이 U10000~U10FFFF 범위 내의 유니코드 문자를 대리 표현(surrogate representation)하는데, 이 새로운 범위의 문자를 supplementary characters 라고 한다.
여전히 단일 char 값으로 UFFFF까지의 유니코드 값을 표현할 수는 있지만, char 대리 쌍(surrogate pair)만이 추가 문자(supplementary characters)를 표현할 수 있다. 쌍의 최초값 또는 high 값은 UD800~UDBFF 범위에, 그리고 마지막값 또는 low 값은 UDC00~UDFFF 범위에 속한다. 유니코드 표준은 이 두 범위를 대리 쌍을 위한 특수 용도로 배정하고 있으며, 표준은 또한 UFFFF를 벗어나는 대리 쌍과 문자 값 사이의 매핑을 위한 알고리즘을 정의한다. 프로그래머는 대리 쌍을 이용하여 유니코드 표준 내의 어떠한 문자라도 표현할 수 있는데, 이런 특수 용도의 16비트 유닛을 UTF-16 이라고 부르며, 자바 플랫폼은 UTF-16을 사용하여 유니코드 문자를 표현한다. char 타입은 이제 UTF-16 코드 유닛으로, 반드시 완전한 유니코드 문자(코드 포인트)가 아니어도 된다.
length 메소드는 단지 char 유닛만을 세기 때문에 추가 문자는 셀 수 없다. 다행히도 J2SE 5.0 API에는 codePointCount(int beginIndex, int endIndex) 라는 새로운 String 메소드가 추가되었다. 이 메소드는 두 인덱스 사이에 얼마나 많은 유니코드 포인트(문자)가 있는지 알려주는데, 인덱스 값은 코드 유닛 또는 char 위치를 참조한다. 식 endIndex - beginIndex 의 값은 length 메소드가 제공하는 값과 동일하며, 이 둘의 차이는 codePointCount 메소드가 반환하는 값과 항상 동일하지는 않다. 텍스트에 대리 쌍이 포함되어 있는 경우에는 길이 수가 확실히 달라진다. 대리 쌍은 하나 또는 두 개의 char 유닛으로 된 단일 문자 코드 포인트를 정의한다.
하나의 문자열에 얼마나 많은 유니코드 문자 코드 포인트가 있는지 알아보려면 codePointCount 메소드를 사용하도록 한다.
private String testString = "abcd\u5B66\uD800\uDF30";
int charCount = testString.length();
int characterCount = testString.codePointCount(0, charCount);
System.out.printf("character count: %d\n", characterCount);
이 예제는 다음 내용을 출력한다.
character count: 6
testString 변수에는 두 개의 흥미로운 문자가 포함되어 있는데, 그것은 '배움(learning)'이라는 뜻의 일본어 문자와 GOTHIC LETTER AHSA 라는 이름의 문자이다. 일본어 문자는 유니코드 코드 포인트 U5B66을 사용하며, 이는 동일한 16진수 char 값 \u5B66을 가진다. 고딕체 글자의 코드 포인트는 U10330이고, UTF-16에서 고딕체 글자는 대리 쌍 \uD800\uDF30이다. 이 쌍은 단일 유니코드 코드 포인트를 표현하므로 전체 문자열의 문자 코드 포인트 수는 7이 아니라 6이 된다.
바이트 수 세기
String 안에는 얼마나 많은 바이트가 있을까? 그 대답은 사용되는 바이트 기반 문자 세트에 의해 결정된다. 바이트 수를 알아보려는 이유 중 하나는 데이터베이스의 문자열 길이 제한 조건을 충족하기 위해서이다. getBytes 메소드는 유니코드 문자를 바이트 기반 인코딩으로 변환하며, 이는 byte[] 를 반환한다. UTF-8 은 바이트 기반 인코딩의 일종이지만, 모든 유니코드 코드 포인트를 정확하게 표현할 수 있다는 점에서 대부분의 다른 바이트 기반 인코딩과는 구별된다.
다음 코드는 텍스트를 byte 값의 배열로 변환한다.
byte[] utf8 = null;
int byteCount = 0;
try {
utf8 = str.getBytes("UTF-8");
byteCount = utf8.length;
} catch (UnsupportedEncodingException ex) {
ex.printStackTrace();
System.out.printf("UTF-8 Byte Count: %d\n", byteCount);
타깃 문자 세트가 생성될 바이트의 수를 결정한다. UTF-8 인코딩은 단일 유니코드 코드 포인트를 1~4개의 8비트 코드 유닛(=1 바이트)으로 변환한다. 문자 a , b , c , d 는 모두 4 바이트만을 요구하는 한편, 일본어 문자(한국어도 같음)는 3 바이트로 변환된다. 또한 고딕체 글자는 4 바이트를 차지한다. 결국 다음의 결과가 나오는 것을 알 수 있다.
UTF-8 Byte Count: 11
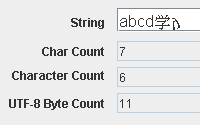
그림 1. 무엇을 세느냐에 따라 문자열의 길이가 달라진다.
요약
추가 문자를 사용하지 않으면 length 와 codePointCount 의 반환 값 간에는 차이점이 없다고 할 수 있다. 하지만 UFFFF 범위를 넘어서는 문자를 사용할 경우에는 길이를 결정하는 다양한 방법에 관해 알아야 할 필요가 있다. 예컨대 미국에서 한국으로 제품을 발송할 경우에는 십중팔구 length 와 codePointCount 가 서로 다른 값을 반환하는 상황이 발생한다. 데이터베이스의 문자 세트 인코딩과 일부 직렬화 포맷은 UTF-8을 최선의 방법으로 권장되고 있는데, 이 경우에도 역시 텍스트 길이는 달라진다. 결국 길이를 어떻게 활용할 것인지에 따라 다양한 측정 옵션을 사용할 수 있다.
추가 정보
본 테크 팁 주제에 관한 자세한 내용을 보려면 다음 리소스를 참조할 것(영문)